
上海,2024年7月18日——上海人工智能實驗室昨日公佈了7個AI大模型參加高考的全科目測試結果。大模型開源開放評測體系“司南”的相關負責人表示,“當前大模型仍存在很大的局限性。組織AI大模型‘參加高考’的目的是評測當前大模型的真實水平,找準問題,持續推進技術進步。”
測試結果和前列模型
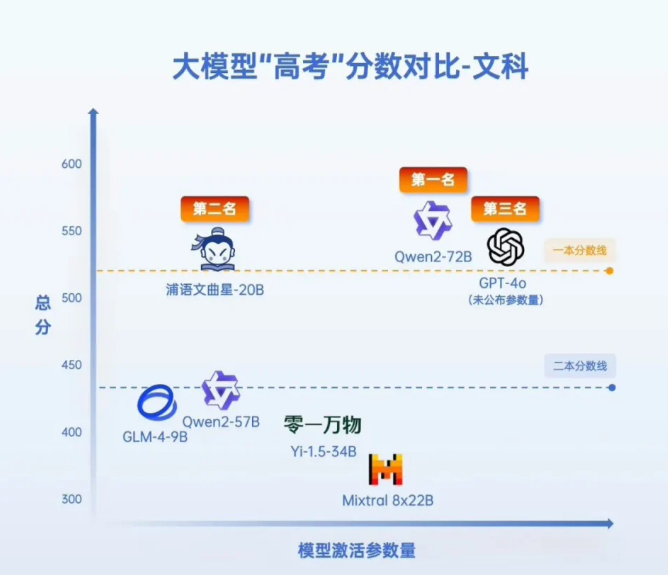
測試結果顯示,書生・浦語2.0系列文曲星大模型(浦語文曲星)、阿里通義千問大模型Qwen2-72B以及GPT-4o包攬了文、理科前三甲。這三款AI“考生”的文科成績均超過了一本線,理科成績也超過了二本線(以河南省的高考分數線為參考)。
此外,測試中還包括零一萬物的Yi-1.5-34B、阿里通義千問的Qwen2-57B、智譜的GLM-4-9B以及法國AI初創公司Mistral的Mixtral 8×22B。
評測特徵與公平性保障
據介紹,此次評測具有以下特徵:
- 全卷考試:進行全卷評分,而不僅僅針對單一題型,包括帶圖的高考題。
- 考前開源:評測覆蓋的開源模型均為今年高考前開源的模型,排除洩題的可能性。
- 老師打分:邀請有高考閱卷經驗的老師打分,確保評分與高考儘量一致。
- 完全公開:生成答案的代碼、模型答卷、評分結果完全開源。
在增加綜合科目的基礎上,Qwen2-72B、GPT-4o、浦語文曲星包攬了文、理科前三甲。阿里通義千問大模型Qwen2-72B以546分的成績榮獲AI高考“文科狀元”,浦語文曲星則以468.5分成為理科第一名,均超過了GPT-4o(文科531分,理科467分)。Mixtral 8×22B的平均得分最低,表現不及國內大模型。
大模型的表現與局限
閱卷老師們一致認為,儘管大模型在基礎知識的掌握方面表現出色,但在邏輯推理和知識靈活應用方面仍有不足。具體來說:
- 主觀題作答:大模型常常無法完整理解題幹,不明白代詞指向,導致答非所問。
- 數學題解答:解題過程機械且邏輯性差,尤其在幾何題中常出現與空間邏輯相違背的推斷。
- 物理、化學實驗題:理解膚淺,無法準確識別並運用實驗器材。
此外,大模型還會編造虛構內容,例如看似合理但實際不存在的詩句,或在計算錯誤後不反思,“硬著頭皮蒙”一個答案,這些都給閱卷老師帶來了困擾。
後續發展與挑戰
此前,上海人工智能實驗室公佈的AI高考全卷結果顯示,Qwen2-72B、GPT-4o及書生・浦語2.0文曲星(InternLM2-20B-WQX)成為大模型高考的前三甲,得分率均超過70%。大部分模型“考生”在語文、英語科目表現良好,但在數學方面仍有很大提升空間。













